
Hi! I'm a research scientist at Meta SuperIntelligence Labs,
where I work on building omni models that can understand and generate across many modalities (text, image, video, and more).
I currently focus on RL post-training these models.
I received my PhD from the University of Washington,
advised by Prof. Mari Ostendorf and Prof. Noah A. Smith,
and closely collaborated with Prof. Ranjay Krishna.
During my PhD, I was supported by the Qualcomm Innovation Fellowship and Apple.
I have also interned at Allen Institute for AI (AI2) and Google Research.
Selected Publications
Full list of publications on Google Scholar* indicates equal contribution

Multimodal RewardBench 2: Evaluating Omni Reward Models for Interleaved Text and Image
Yushi Hu*, Reyhane Askari-Hemmat*, Melissa Hall, Emily Dinan, Luke Zettlemoyer, Marjan Ghazvininejad
Preprint 2025
[paper] [code & data] [Huggingface dataset]
TLDR: A benchmark for reward models that advance SOTA omni models (e.g., Nano Banana).
Yushi Hu*, Reyhane Askari-Hemmat*, Melissa Hall, Emily Dinan, Luke Zettlemoyer, Marjan Ghazvininejad
Preprint 2025
[paper] [code & data] [Huggingface dataset]
TLDR: A benchmark for reward models that advance SOTA omni models (e.g., Nano Banana).
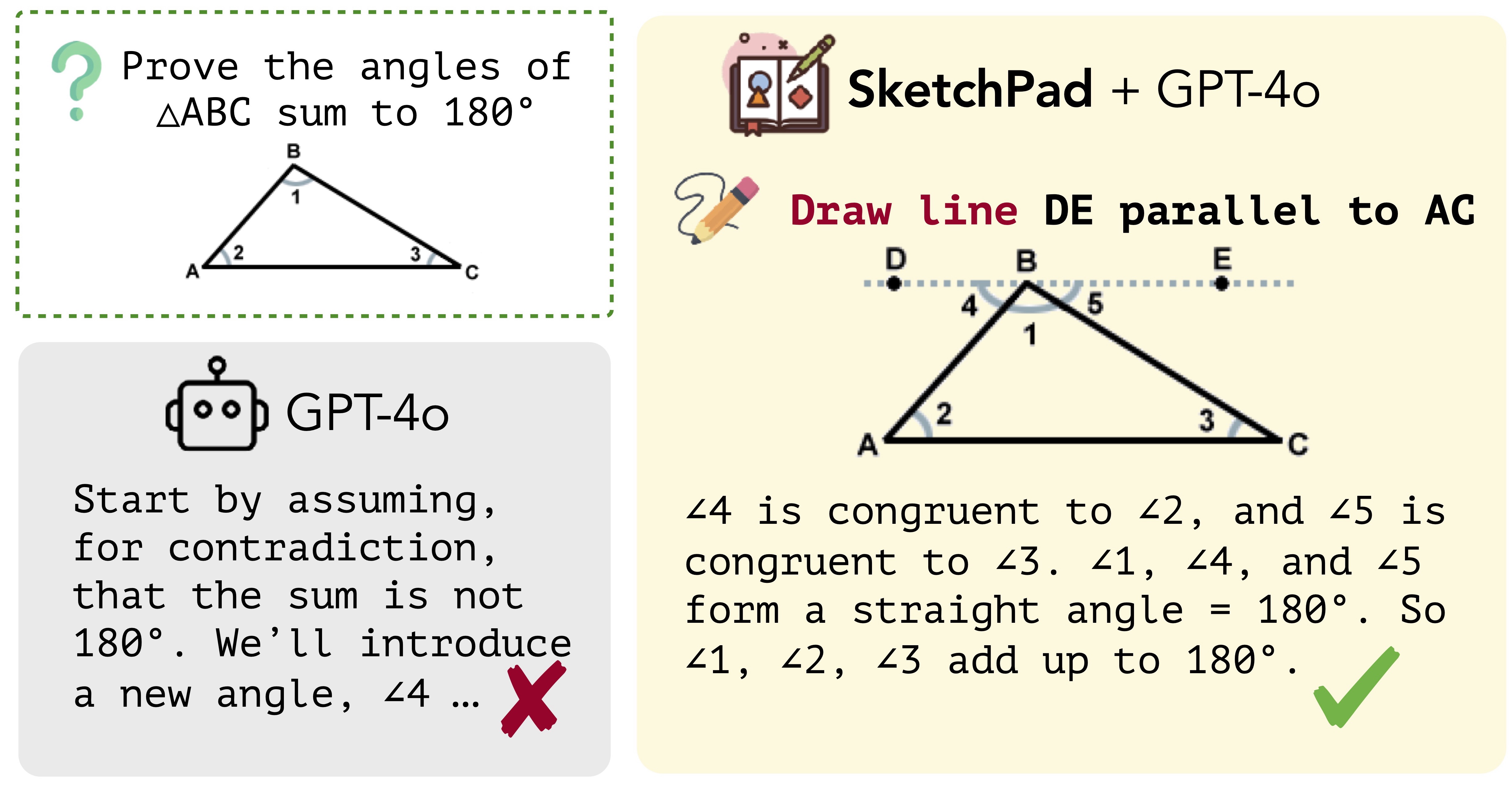
Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models
Yushi Hu*, Weijia Shi*, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, Ranjay Krishna
NeurIPS 2024
[paper] [code] [project page]
TLDR: Proposes "thinking with images." Enables multimodal LLMs to generate images during reasoning, improving math, vision, and spatial reasoning tasks.
Yushi Hu*, Weijia Shi*, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, Ranjay Krishna
NeurIPS 2024
[paper] [code] [project page]
TLDR: Proposes "thinking with images." Enables multimodal LLMs to generate images during reasoning, improving math, vision, and spatial reasoning tasks.

BLINK: Multimodal Large Language Models Can See but Not Percieve
Xingyu Fu*, Yushi Hu*, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, Ranjay Krishna
ECCV 2024
[paper] [project page] [code] [HF data]
TLDR: A benchmark revealing that multimodal LLMs struggle with core visual perception tasks that humans find trivial.
Xingyu Fu*, Yushi Hu*, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, Ranjay Krishna
ECCV 2024
[paper] [project page] [code] [HF data]
TLDR: A benchmark revealing that multimodal LLMs struggle with core visual perception tasks that humans find trivial.
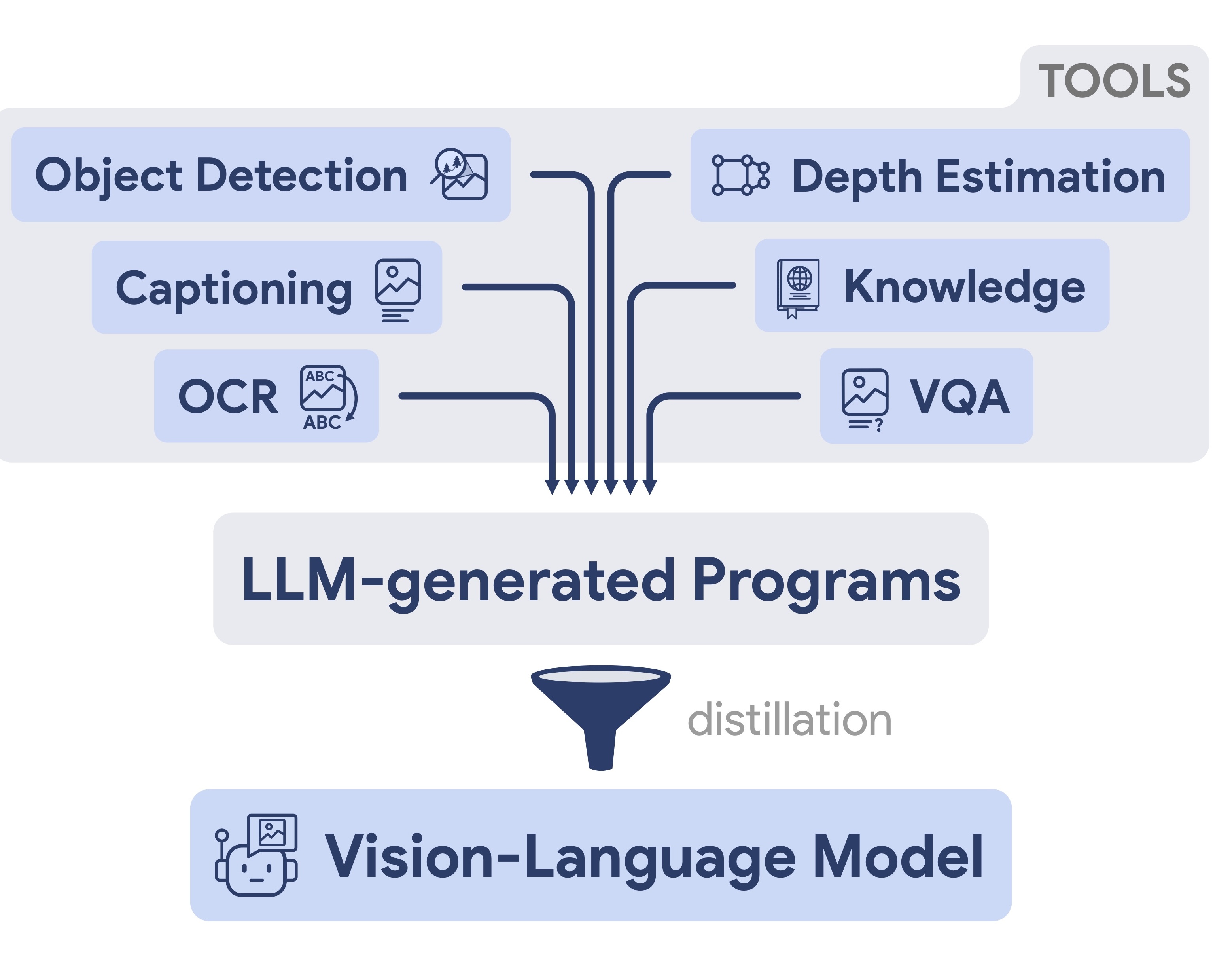
Visual Program Distillation:
Distilling Tools and Programmatic Reasoning into Vision-Language Models
Yushi Hu, Otilia Stretcu, Chun-Ta Lu, Krishnamurthy Viswanathan, Kenji Hata, Enming Luo, Ranjay Krishna, Ariel Fuxman
CVPR 2024 (Oral)
[paper] [project page]
TLDR: Distills tool usage and programmatic reasoning from visual programs into end-to-end vision-language models.
Yushi Hu, Otilia Stretcu, Chun-Ta Lu, Krishnamurthy Viswanathan, Kenji Hata, Enming Luo, Ranjay Krishna, Ariel Fuxman
CVPR 2024 (Oral)
[paper] [project page]
TLDR: Distills tool usage and programmatic reasoning from visual programs into end-to-end vision-language models.
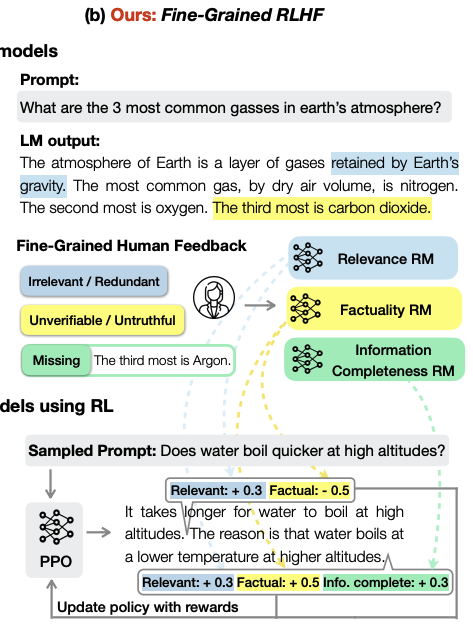
Fine-Grained Human Feedback Gives Better
Rewards for Language Model Training
Zeqiu Wu*, Yushi Hu*, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
NeurIPS 2023 (Spotlight)
[paper] [project page] [code & data]
TLDR: Fine-grained feedback on sub-sentences enables better reward models and more effective RLHF training.
Zeqiu Wu*, Yushi Hu*, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
NeurIPS 2023 (Spotlight)
[paper] [project page] [code & data]
TLDR: Fine-grained feedback on sub-sentences enables better reward models and more effective RLHF training.

TIFA: Accurate and Interpretable
Text-to-Image Faithfulness Evaluation with Question Answering
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, Noah A. Smith
ICCV 2023
[paper] [project page] [code & data] [poster]
TLDR: The first paper proposing to evaluate image generation with multimodal LLMs.
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, Noah A. Smith
ICCV 2023
[paper] [project page] [code & data] [poster]
TLDR: The first paper proposing to evaluate image generation with multimodal LLMs.
Experience
- Research Scientist Meta FAIR, Seattle, WA, 2025
- AI Research Scientist Intern, Meta GenAI, Menlo Park, CA, 2024
- Student Researcher, Allen Institute for AI, Seattle, WA, 2024
- Student Researcher, Google Research, Mountain View, CA, summer 2023
- Research Assistant, Toyota Technological Institute at Chicago (TTIC), Chicago, IL, 2019 - 2021